|
I am a fourth-year Ph.D. student at the Hong Kong University of Science and Technology (HKUST), supervised by Prof. Qifeng Chen. In 2020, I received my Bachelor's Degree in Automation, Zhejiang University with a National Scholarship from Chu Kochen Honors College . From June 2022 to December 2022, I worked as a research intern at MSRA, supervised by Bo Zhang , Dong Chen, and Fang Wen. After that, I was fortunate to work at Tencent AI Lab with Xiaodong Cun , Yong Zhang, Xintao Wang and Ying Shan on project FateZero about video diffusion model I was a student researcher at Google Research mentored by Zhengzhong Tu, Mauricio Delbracio, Hossein Talebi.Now I am working at Adobe with Taesung Park and Jimei Yang on video editing and generation. 我正在寻找2024年秋季入职的全职岗位, 欢迎邮件联系 I will graduate at 2024 Fall. Drop me an Email if your are recruting! Email / CV / Google Scholar / Github |

|
|
|
|
Currently, I am working on image / video generation and editing using AIGC techniques! |
 |
ECCV, 2024 project page |
|
|
Chenyang Qi, Xiaodong Cun , Yong Zhang, Chenyang Lei, Xintao Wang , Ying Shan, Qifeng Chen ICCV Oral, 2023 arxiv / code / project page 
Editing your video via pretrained Stable Diffusion model without training.
|

|
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Yue Ma*, Yingqing He*, Hongfa Wang, Andong Wang, Chenyang Qi, Chengfei Cai, Xiu Li, Zhifeng Li, Heung-Yeung Shum, Wei Liu, Qifeng Chen, arXiv, 2024 Project page / arXiv / Github 
|
 |
Jiwen Yu, Xiaodong Cun , Chenyang Qi , Yong Zhang, Xintao Wang, Ying Shan, Jian Zhang
ArXiv, 2023
|
 |
Yue Ma, Xiaodong Cun, Yingqing He, Chenyang Qi, Xintao Wang, Ying Shan, Xiu Li , Qifeng Chen
ArXiv, 2023
|
 |
Ge Yuan, Xiaodong Cun, Yong Zhang, Maomao Li, Chenyang Qi, Xintao Wang, Ying Shan, Huicheng Zheng NeurIPS, 2023 project page / code Face identity customization in diffusion model |
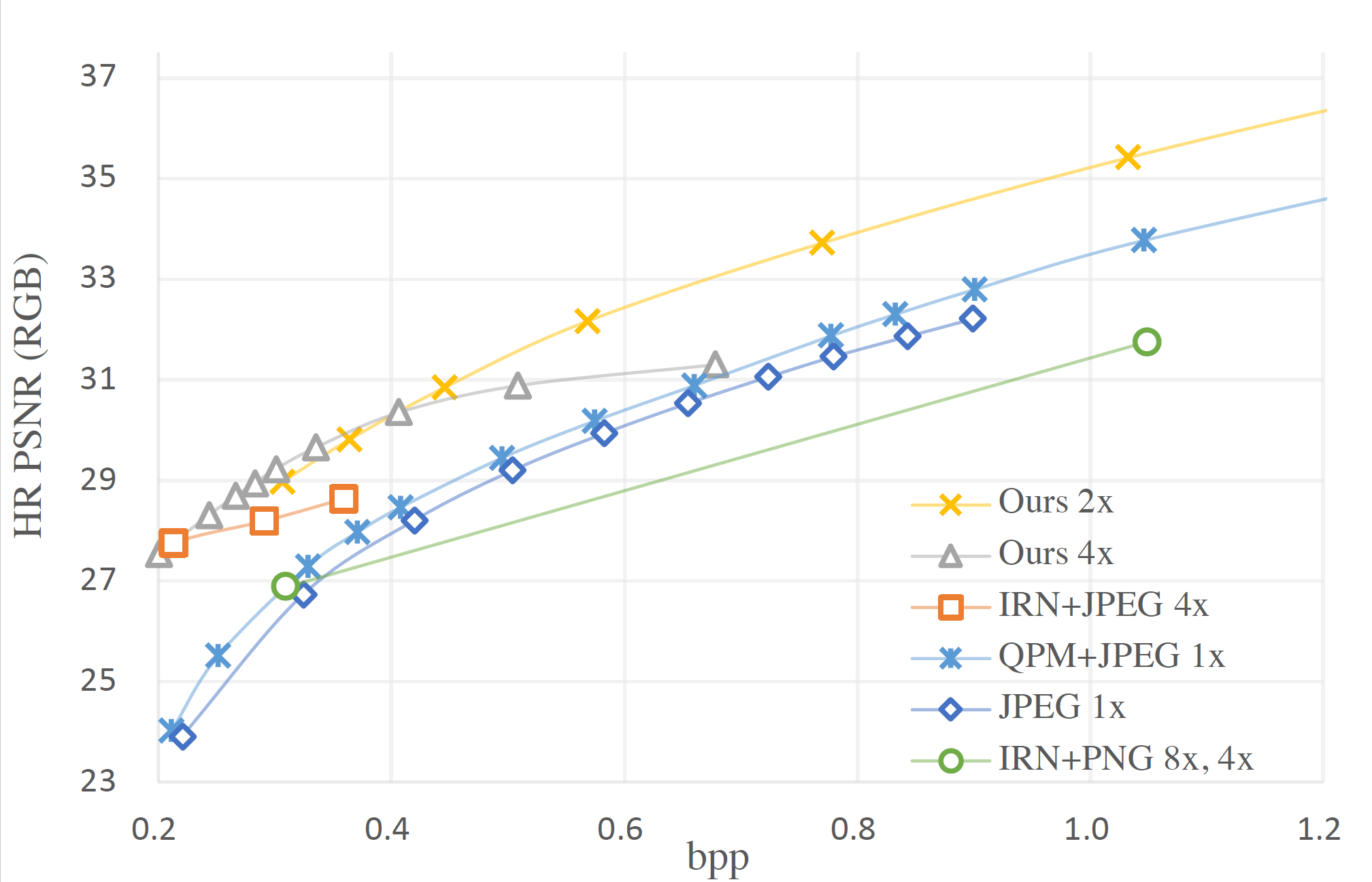 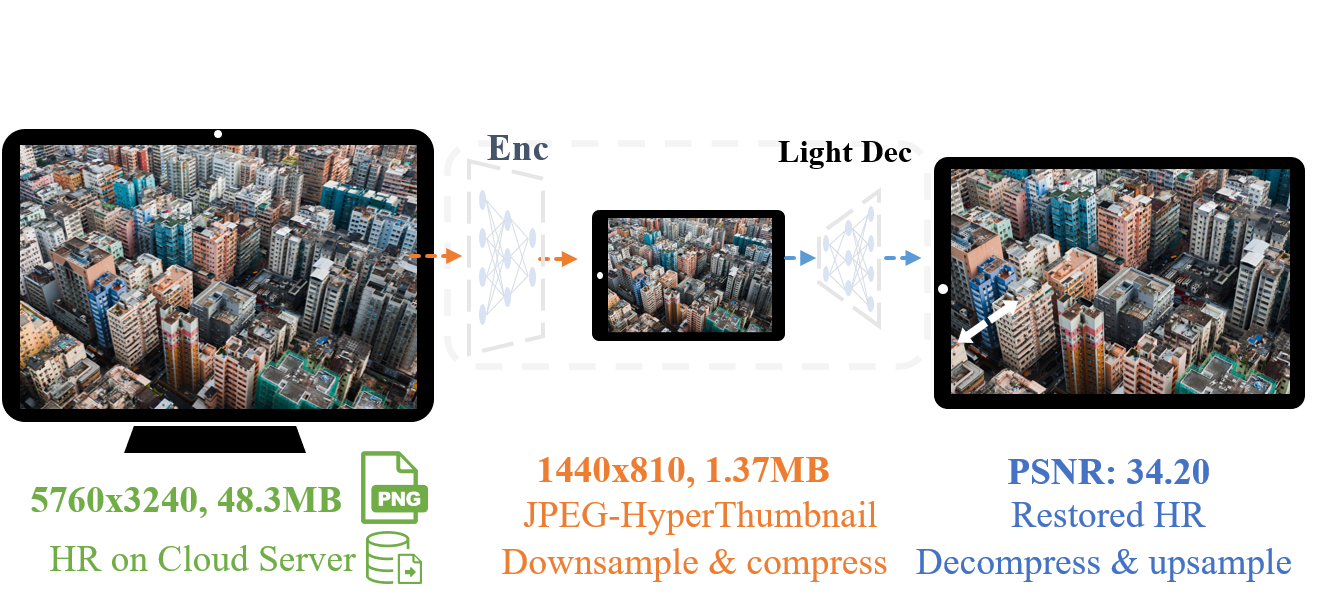 |
Chenyang Qi,* Xin Yang*, Ka Leong Cheng, Ying-Cong Chen, Qifeng Chen CVPR, 2023 arxiv / code Image upscaling with learnable frequency-domain quantization to achieve 6K real-time speed and best rate-distortion. |
|
|
Bowen Zhang*, Chenyang Qi*, Pan Zhang, Bo Zhang, HsiangTao Wu, Dong Chen, Qifeng Chen, Yong Wang, Fang Wen CVPR, 2023 arxiv / code / project page Identity-preserving talking head generation utilizing dense landmarks and
spatial-temporal enhancement with GAN priors.
|
|
|
Chenyang Qi*, Junming Chen*, Xin Yang, Qifeng Chen ACM Multimedia, 2022 arxiv / code / project page An extremely efficient (700X speedup) buffer-based framework for online video denoising. |
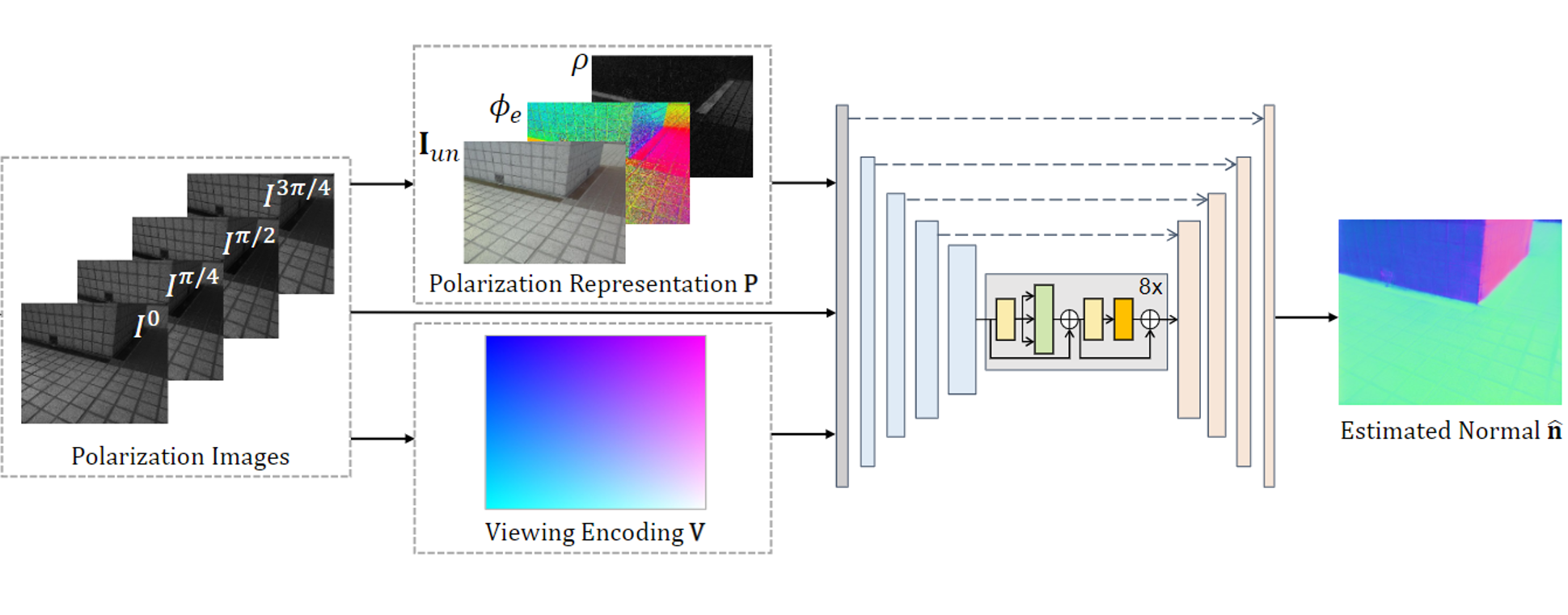  |
Chenyang Lei*, Chenyang Qi*, Jiaxin Xie*, Na Fan, Vladlen Koltun , Qifeng Chen CVPR, 2022 arxiv / code / project page Scene-level normal estimation from a single polarization image using physics-based priors. |


|
|

|
July, 2023 - December, 2023 |
|||

|
Jan, 2023 - June, 2023 |
|||

|
June, 2022 - December, 2022 |
|
|
|
Thanks Dr. Jon Barron for sharing the source code of his personal page. |