Publications
I am fortunate to collaborate with talented students and researchers around the world on multimodal generative models for image and video synthesis. See Google Scholar for the complete list. (* equal contribution)


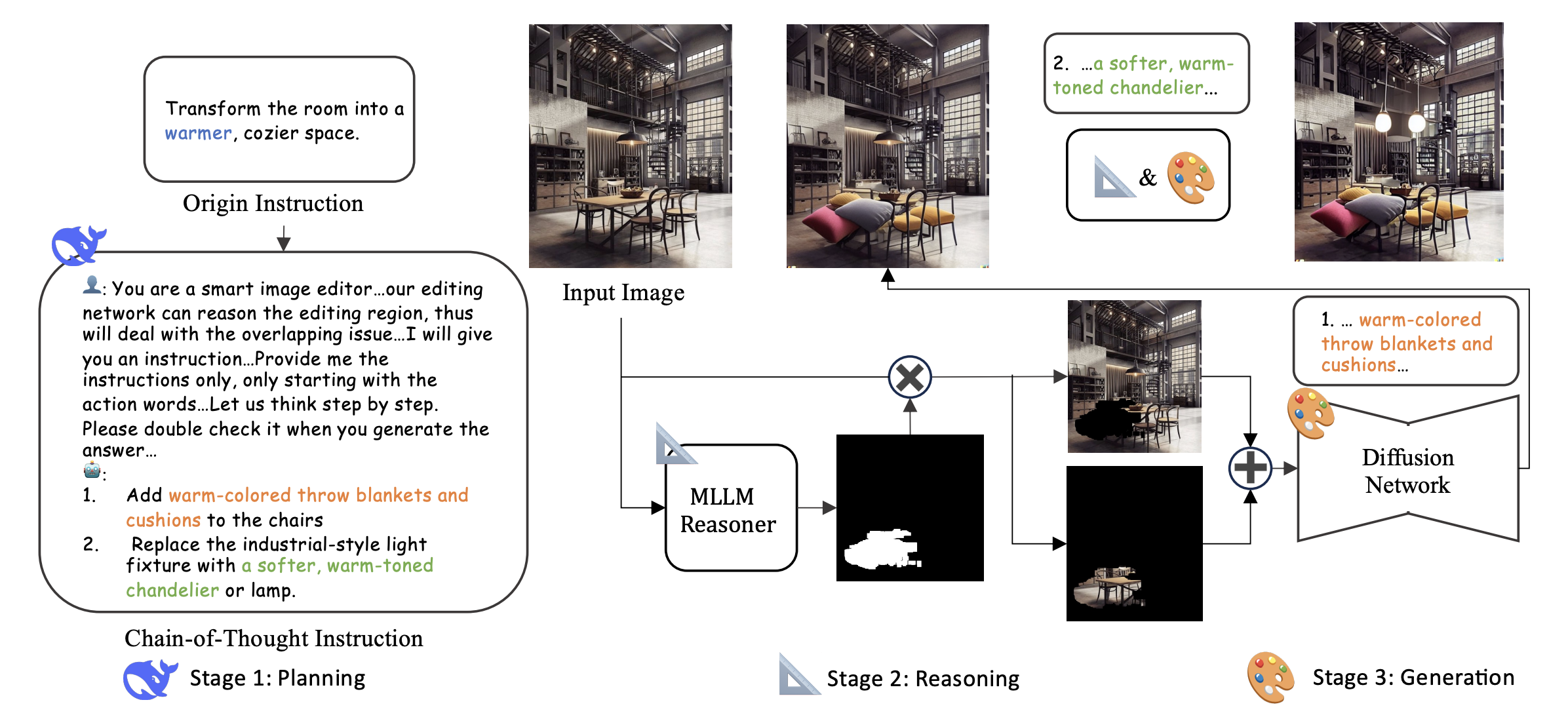

ECCV 2024
Work done during my internship at Google Research.
ICCV 2023 · Oral

Edit your video with a pretrained Stable Diffusion model — no training required (e.g., replace a jeep with a Porsche, or restyle sunflowers à la Van Gogh).







NeurIPS 2023
Face identity customization in diffusion models.
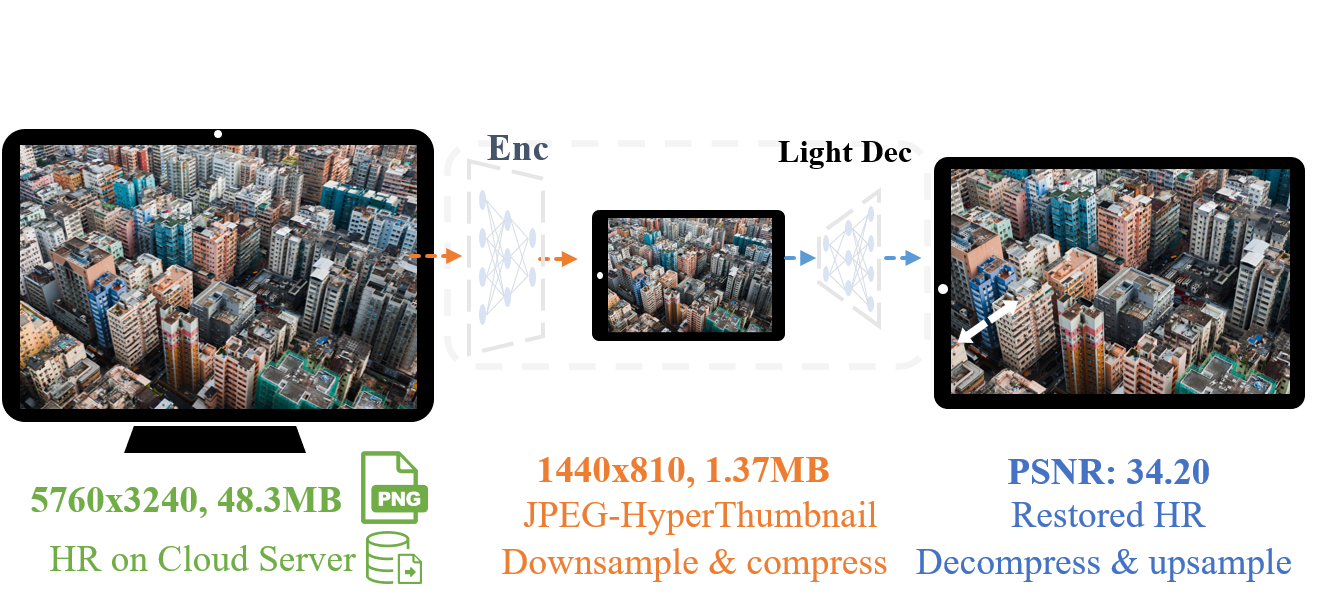
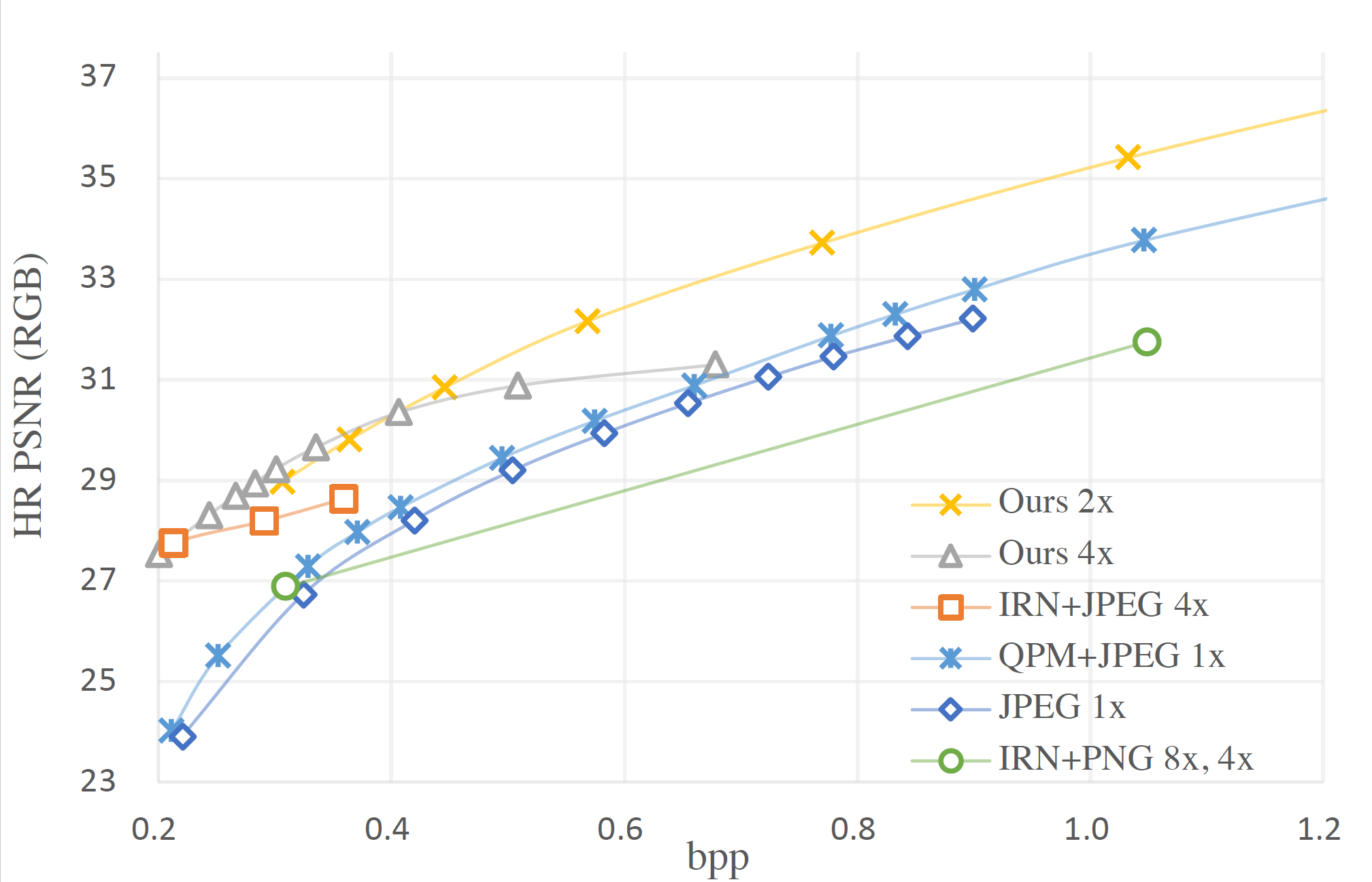
CVPR 2023
Learnable frequency-domain quantization for 6K real-time image rescaling with the best rate-distortion trade-off.
CVPR 2023
Identity-preserving talking-head generation with dense landmarks and spatial-temporal enhancement.
ACM MM 2022
An extremely efficient (700× speedup) buffer-based framework for online video denoising.

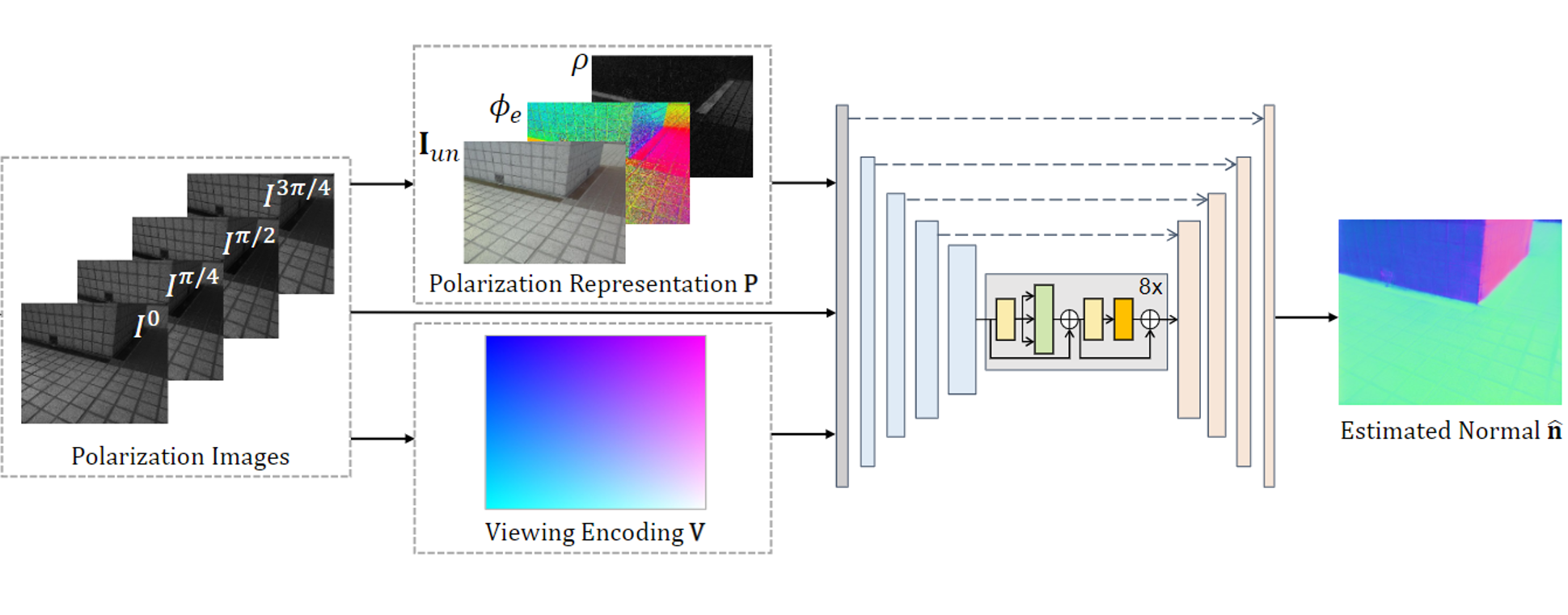
CVPR 2022
Scene-level normal estimation from a single polarization image using physics-based priors.